How to Vet a Stock Screen Before Trusting the Score
A deeper workflow for auditing stock-screen scores with component drivers, stale-data checks, SEC filings, market context, and rejection notes.
Published 6/23/2026
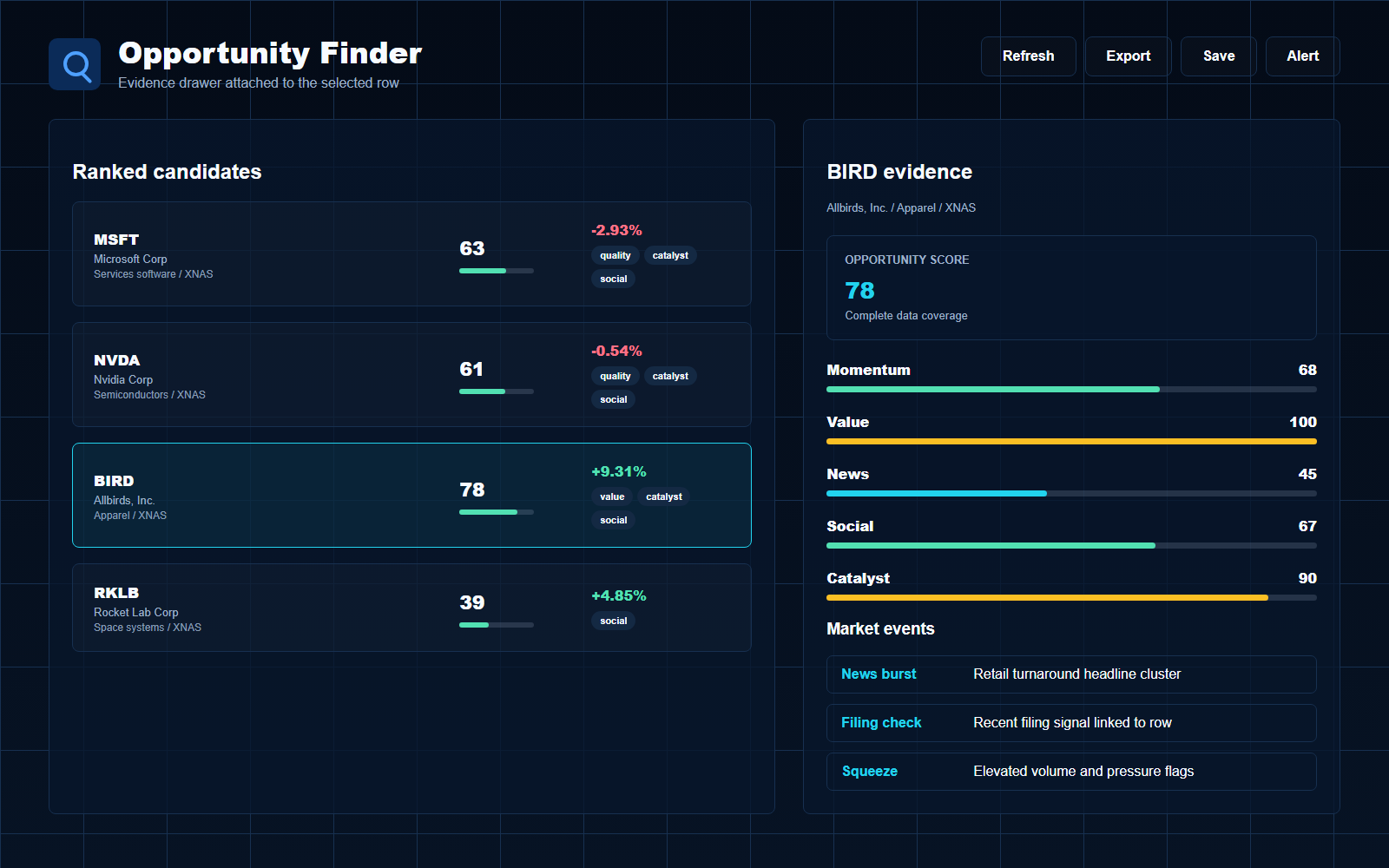
A stock-screen score can look precise even when the underlying question is messy. Scores combine inputs, and every input has assumptions: how fresh it is, how it is normalized, which universe it covers, and whether missing data is ignored or penalized. Before trusting the score, audit what it is really saying.
The goal is not to eliminate screens. A good screen is useful because it organizes attention. The goal is to stop confusing organization with proof. A score can help you find a candidate, but the source trail decides whether the candidate deserves research time.

Break the score into drivers
A composite score should never be read as one thing. Momentum, value, quality, news, filings, social attention, and short-interest context each answer different questions. If a ticker ranks well because one component is extreme, the review should focus on that component first.
Driver analysis also reveals mismatches. A company may look attractive on valuation because earnings temporarily spiked. It may look strong on momentum because of a one-day news event. It may look active socially because of promotion rather than durable investor interest.
- Identify the top two components driving the score.
- Check whether the score is broad-based or single-factor.
- Review outlier inputs before accepting the composite result.
- Separate durable fundamentals from short-lived market activity.
- Record which driver would need to persist for the idea to matter.
Check freshness and coverage
A stale field can make a score look better or worse than reality. Market data, filings, fundamentals, short-interest information, and news coverage update on different schedules. A workflow that ignores those schedules will compare current signals with old context.
Coverage matters too. A small company may have limited analyst coverage, fewer filings, thinner trading, or patchier data. That does not make the company uninvestable, but it does change the confidence level of the screen.
- Check when each major data group last refreshed.
- Flag rows with missing or partial fundamental coverage.
- Treat stale price, filing, or short-interest inputs as review blockers.
- Adjust confidence for thin liquidity and limited coverage.
- Do not compare high-confidence and low-confidence rows as equals.
Read the source trail before promoting a ticker
Investor.gov and the SEC point investors toward EDGAR for public-company filings. That matters for screen review because a score cannot capture the full text of risk factors, management discussion, legal proceedings, liquidity notes, or accounting changes. The source trail gives the row a reality check.
The best habit is to promote a ticker only after a quick source pass. That pass does not need to be exhaustive, but it should verify that the company exists in the form the screen implies, that recent filings do not contradict the screen, and that the main catalyst or metric is not misunderstood.
- Open the latest 10-K or 10-Q for business and risk context.
- Check recent 8-K filings for material events.
- Review company news for the source of unusual price or volume.
- Check whether the ticker has corporate actions, name changes, or symbol changes.
- Save source links with the screening note.
Use rejection notes as feedback
Rejected rows are not wasted time. They are feedback about the screen. If many rows fail because of stale data, fix the freshness threshold. If many fail because of low liquidity, adjust the liquidity filter. If many fail because the catalyst is weak, change the catalyst rule.
A screen improves when the researcher records why rows failed. Without those notes, the same weak matches will keep returning and the workflow will feel noisy even if the scoring model is doing exactly what it was asked to do.
- Reject with a reason, not just a click.
- Group rejection reasons by data, liquidity, quality, source, or fit.
- Review recurring rejection patterns monthly.
- Tighten filters only after seeing repeated evidence.
- Keep accepted and rejected examples for future calibration.
A score can rank attention. It cannot verify the facts behind that attention.
Make the score explainable
A composite stock score is useful only if the researcher can decompose it. A ticker that ranks well because every component is solid deserves a different review from a ticker that ranks well because one extreme input overwhelms several weak ones. A source-trail workflow turns the score from a black box into a set of claims that can be checked.
Start by identifying the dominant inputs. Was the row pulled up by momentum, liquidity, valuation, growth, profitability, analyst revision, short-interest context, or a recent event? Then ask whether those inputs are current and relevant to the screen objective. A stale data point can make a row look more attractive than it is. A correct but irrelevant data point can distract from the actual question.
- Break the score into component drivers before reading the company story.
- Check data freshness for each major driver.
- Attach source links for filings, price data, estimate context, or event notes.
- Flag rows where a missing value may have distorted the score.
- Write the reason a ticker remains in the queue after the source check.
Close rejected ideas cleanly
Rejected rows are part of the research asset. A clean rejection note prevents the same weak idea from being rediscovered every time the screen runs. It also helps improve filters. If many rejected rows fail because the same data field is stale, the screen needs a data-readiness gate. If many fail because the same business model does not fit the thesis, the screen needs a better filter.
- Use short rejection categories such as stale data, wrong business model, weak source support, or catalyst expired.
- Review rejection patterns to improve the screen.
- Keep rejected rows searchable for future audits.
- Do not promote a row without a source-backed reason simply because the score is high.
- Reopen a rejected idea only when the original failure reason has changed.
This also makes handoffs easier. If another researcher, future you, or a portfolio review process opens the file, the note should explain the score without requiring a tour through the original screen. The reader should know what triggered the match, which sources were checked, what was rejected, and what would justify another look. That is the difference between a screen result and a research artifact.
This is how screening becomes research rather than sorting. The source trail makes the ranking explainable, and the rejection trail makes the process better over time.